Configuration de mise en commun de connexion avancée de base de données¶
- Les connexions de base de données sont des ressources précieuses et comme tels sont gérées avec soin :
ils sont lourds à créer et à maintenir pour le serveur de base de données elle-même, car ils sont généralement des processus enfants du processus serveur SGBD
étant des processus que signifie que la création d’une connexion n’est pas un processus de zéro-coût c’est pourquoi nous devrions éviter de créer des connexions que nous avons besoin pour vous connecter à une base de données, mais nous devrions tendent à les créer à l’avance afin de minimiser l’impact du temps nécessaire pour créer leur sur le temps nécessaire pour servir une requête.
par suite du fait qui nécessitent une connexion des ressources non négligeables sur le serveur de bases de données SGBD ont tendance à
limiter le nombre de connexions disponibles globalement (PostgreSQL par défaut a une limite fixée à 100)
limiter la durée de vie des connexions créées afin de décourager les clients de conserver les connexions depuis vraiment longtemps
Desservie par un pool de connexions vise à maintenir les connexions à une base de données sous-jacente entre les requêtes. L’avantage est que la liaison est établie doivent seulement se produisent une fois sur la première demande, tandis que les requêtes suivantes utilisent des connexions existantes et obtenir un avantage de performance en conséquence.
OK, maintenant, allons dans les détails de GeoServer. Dans la plupart GeoServer DataStores vous avez la possibilité d’utiliser le _ JNDI [#f1] ou le magasin standard qui signifie essentiellement que vous pouvez avoir GeoServer gérer le pool de connexions pour vous ou vous pouvez le configurer à l’extérieur (de dans le serveur d’applications de choix) et ensuite faire GeoServer pencher dessus pour obtenir des connexions. Niveau de référence est, une façon ou l’autre, vous serez toujours fin-haut à l’aide d’un pool de connexions dans GeoServer.
Paramètres de Pool de connexion interne GeoServer¶
Chaque fois qu’un magasin de données soutenue par une base de données est ajouté à Geoserver une piscine de connexion interne, qui repose sur Apache Commons DBCP [# F2] _, est créé par défaut. Ce pool de connexion est configurable, mais laissez-moi vous dire ceci dès le départ, le nombre de piscine paramètres de configuration que nous exposons est un sous-ensemble des possibles, bien que le plus intéressant sont là. À savoir il ya quelques-uns qui vous voudrez peut-être personnaliser. Voici ci-dessous vous pouvez trouver plus de détails sur certains paramètres de connexion disponibles.
Connexions maxi.
Le nombre maximal de connexions que pouvant accueillir la piscine. Lorsque le nombre maximal de connexions est dépassé, les demandes supplémentaires qui nécessitent une connexion de base de données seront interrompus jusqu’à ce qu’une connexion du pool devient disponible et finalement arrive à expiration si ce n’est pas possible dans le délai précisé dans le délai de connexion. * Le nombre maximum de connexions limite le nombre de requêtes simultanées qui peut être effectuée sur la base de données *.
** min connexions **
- Le nombre minimum de connexions que tiendra la piscine. Ce nombre de connexions est tenu, même lorsqu’il n’y a aucune demande active. Lorsque ce nombre de connexions est dépassé en raison de servir les requêtes entrantes des connexions supplémentaires sont ouverts jusqu’à ce que la piscine atteint sa taille maximale (décrit ci-dessus). Les implications de ce nombre sont multiples :
-1 - si il est de très loin les connexions max cela pourrait limiter la capacité de la GeoServer de réagir rapidement aux imprévus ou aléatoire lourde charge des situations due au fait qu’il faut un temps non négligeable pour créer une nouvelle connexion. Toutefois, cette configuration est très bonne, quand le SGBD est très sollicité puisqu’il tend à utiliser comme moins des connexions que possible en tout temps.
-2 - s’il est très proche des que connexions max valeur la GeoServer sera très rapide pour répondre à la situation de chargement aléatoire. Cependant dans ce cas le GeoServer mettrait un lourd fardeau sur SGBD épaules comme le scrutin va essayer de tenir les connexions nécessaires à tout moment.
** valider les connexions **
Drapeau indiquant si les connexions à partir de la piscine doivent être validés avant d’être utilisés. Une connexion dans la piscine peut devenir invalide pour un certain nombre de raisons, y compris panne de réseau, base de données serveur timeout, etc .. Le bénéfice de la mise ce drapeau est qu’une connexion valide ne sera jamais utilisé ce qui peut empêcher les erreurs client. L’inconvénient de mettre le drapeau est qu’une petite pénalité de performance est versée afin de valider les connexions lorsque la connexion est emprunté à la piscine depuis la validation se fait par l’envoi de la requête au serveur Smal. Cependant, le coût de cette requête est généralement de petite taille, comme un exemple sur PostGis la requête de validation * Sélectionnez 1 *.
Taille de l’extraction
Le nombre d’enregistrements extraite de la base de données dans chaque circonscription de réseau. Si ils sont réglés trop bas (< 50) latence du réseau affectera négativement la performance, si réglé trop haut, il peut consommer une part importante de la mémoire de GeoServer et poussez-le vers une * de mémoire erreur *. Par défaut, 1000, il pourrait être avantageux de le pousser à un nombre plus élevé si la requête de base de données typique lit beaucoup plus de données que cela, et il y a assez de mémoire pour stocker les résultats tas
délai de connexion, délai d’attente de la connexion
Temps, en secondes ** **, le pool de connexion va attendre avant d’abandonner sa tentative d’obtenir une nouvelle connexion à partir de la base de données. Par défaut à 20 secondes. Ce délai débute dans des conditions de charges lourdes lorsque le nombre de demandes nécessitant une connexion à un certain DB sont beaucoup plus nombreux le nombre de connexions disponibles dans la piscine, donc certaines demandes pourraient obtenir des messages d’erreur en raison de délais d’attente tout en acquérant les une connexion. Cette condition est pas en soi problématique car, généralement, une demande ne pas utiliser une connexion DB pour l’ensemble de son cycle de vie où on n’a pas besoin de 100 connexions à portée de main pour répondre à 100 demandes; Cependant, nous devons nous efforcer de limiter cette condition car il serait la file d’attente les discussions sur le pool de connexion après qu’ils auraient alloué mémoire (par exemple pour le rendu). Nous allons revenir à cela plus tard.
** ouvert max préparé des déclarations **
Nombre maximal de requêtes préparées gardé ouvert et mis en cache pour chaque connexion dans le pool.
** max wait **
nombre de ** secondes ** le pool de connexions attendra avant d’expirer essayant d’obtenir une nouvelle connexion (par défaut, 20 secondes)
** validation connexion **
Il force GeoServer pour vérifier que les connexions empruntées à la piscine sont valides (c’est-à-dire non fermé sur le côté de SGBD) avant de les utiliser.
** Test alors que ralenti **
Tester périodiquement si les connexions sont toujours valables aussi bien que ralenti dans la piscine. Parfois effectuer une requête de test à l’aide d’une connexion inactive peut rendre le magasin de données indisponible pendant un certain temps. Souvent la cause de ce comportement pénible est liée à un pare-feu de réseau placé entre Geoserver et la base de données qui forcent la fermeture des connexions TCP ralenties sous-jacent.
** Les expulse exécuter périodicité **
Nombre de ** secondes ** entre objet inactif expulse s’exécute.
** Temps ralenti max connexion **
Nombre de ** secondes ** une connexion a besoin pour rester inactif avant que l’expulse commence à envisager de fermer.
** Tests d’expulse par course **
Nombre de connexions vérifiées par l’expulse de connexion inactive pour chacune de ses pistes.
Examen des instructions préparées¶
Instructions préparées servent de bases de données afin d’éviter la re-planification de l’accès aux données chaque fois, le plan est fait qu’une seule fois dès le départ, et tant que l’instruction est mise en cache, le plan n’a pas besoin d’être re-calculé.
Dans les applications d’affaires extraire une petite quantité de données à la fois ce qui est bénéfique pour la performance, toutefois, dans ceux de nature spatiale, où nous récupérons typiquement des milliers de lignes, l’avantage est limité, et parfois, se transforme en un problème de performance. Ceci est le cas avec PostGIS, qui est en mesure de régler le plan d’accès en inspectant le BBOX demandé, et de décider si une analyse séquentielle est préférable (le BBOX accède vraiment la plupart des données) ou en utilisant l’index spatial est meilleure place. Donc, en règle générale, lorsque vous travaillez avec PostGis, il est préférable de ne pas activer les requêtes préparées.
Autres bases de données, il n’y a pas de choix, Oracle actuellement fonctionne uniquement avec les commandes préparées, SQL server uniquement sans eux (cela est souvent lié aux limitations de la mise en œuvre que des questions spécifiques de base de données).
Il ya une hausse d’utiliser l’instruction préparée cependant : aucune attaque d’injection sql n’est possibles lors de leur utilisation. Code de GeoServer s’efforce d’éviter ce genre d’attaque lorsque vous travaillez sans instructions préparées, mais leur permettant fondamentalement empêche l’attaque via les paramètres de filtre.
Conclusions¶
En résumé, lors de la création d’entrepôts de données standard pour servir les données vectorielles de SGBD dans GeoServer vous devez vous rappeler qu’en interne un pool de connexion sera créé. Cette approche est la plus simple à mettre en œuvre, mais peut conduire à une répartition inefficace des connexions entre différents magasins dans les cas suivants :
Si nous avons tendance à séparer les tables dans des schémas différents, cela conduira à la nécessité pour la création de plusieurs banques pour les servir puisque GeoServer fonctionne encore mieux si le paramètre « schéma » est spécifié, cette attaque à la création de pools de connexions (pour la plupart inutiles)
Si nous voulons créer des magasins dans les différents espaces de travail à la base de données même ceci mènera à nouveau à une duplication inutile des pools de connexions en magasin différent, conduisant à une utilisation inefficace des connexions
Longue histoire courte du fait que la piscine est interne à l’égard des magasins peut conduire à une utilisation inefficace des connexions aux SGBD sous-jacent, car ils seront scindés entre plusieurs magasins limitant l’extensibilité de chacun d’eux: en effet avoir 100 connexions partagée entre N DataStore normal imposer des limites au nombre maximal que chacun peut utiliser, sinon, si nous avons réussi à maintenir les connexions en une seule piscine partagée, à son tour, avec les différents DataStore nous parvenir à un partage plus efficace entre le magasin que, comme un Ainsi, un seul magasin sous haute charge pourrait évoluer pour utiliser toutes les connexions disponibles.
Configuration d’un pool de connexion JNDI avec Tomcat¶
Magasin de nombreuses données dans GeoServer offrent la possibilité d’exploiter Java Naming and Directory Interface ou « JNDI <http: en.wikipedia.org/wiki/java_naming_and_directory_interface=”“>’ _. pour gérer les pools de connexions. JNDI permet à des composants dans un système de Java pour chercher d’autres objets et les données par un nom prédéfini. Une utilisation courante de JNDI est de mettre en place un pool de connexions afin d’améliorer la gestion des ressources de base de données.</http:>
Afin de mettre en place un pool de connexions, Tomcat doit être fournie avec un pilote JDBC pour la base de données utilisée et les configurations de piscine nécessaire. Habituellement, le pilote JDBC peut être consultée sur le site du fournisseur SGBD ou peut être disponible dans le répertoire d’installation de base de données. C’est important de savoir puisque nous ne sommes pas habituellement autorisés à les redistribuer.
Le pilote JDBC pour la création de pool de connexions à être partagés via JNDI doit être placé dans le répertoire de ‘’ $TOMCAT_HOME/lib ‘’, où ‘’ $TOMCAT_HOME’’ est le répertoire sur lequel Tomcat est installé.
Note
Assurez-vous de supprimer le pilote JDBC du dossier ‘’ WEB-INF/lib ‘’ Geoserver lorsque copiées dans les librairies de Tomcat partagé, pour éviter des problèmes dans l’utilisation d’entrepôts de données JNDI.
La configuration est très similaire entre les différentes bases de données. Ici ci-dessous quelques exemples typiques seront décrites.
Configuration de PostgreSQL JNDI¶
Pour configurer un pool de PostgreSQL JNDI, il faut supprimer le pilote JDBC Postgres (il devrait être nommé : file:’postgresql-X.X-XXX.jdbc3.jar ”) de la GeoServer : file:’WEB-INF/lib‘ dossier et mettez-le dans la : file:’TOMCAT_HOME/lib” dossier.
Installation de Tomcat¶
La première étape à effectuer pour la création d’une DataSource JNDI (pool de connexion) est d’éditer le fichier context.xml à l’intérieur du répertoire ‘’ $TOMCAT_HOME/conf ‘’. Ce fichier contient les différentes ressources JNDI configurés pour Tomcat. Dans ce cas, nous allons configurer une DataSource JNDI pour une base de données PostgreSQL. Si le fichier n’est pas présent, vous devez créer et ajouter un contenu semblable à la suivante:
<Context>
<Resource
name="jdbc/postgres" auth="Container" type="javax.sql.DataSource"
driverClassName="org.postgresql.Driver"
url="jdbc:postgresql://localhost:5432/testdb"
username="admin"
password="admin"
maxActive="20"
maxIdle="10"
maxWait="10000"
minEvictableIdleTimeMillis="300000"
timeBetweenEvictionRunsMillis="300000"
validationQuery="SELECT 1"/>
</Context>
Note
Si le fichier est déjà présent, n’ajoutez pas le ‘<Context></Context>’ étiquettes.
Dans l’extrait de code XML précédent, nous avons configuré une connexion à une base de données de PostrgreSQL appelé ** testdb ** qui ont le nom d’hôte comme * localhost * et numéro de port égales à * 5432 *.
Note
Notez que l’utilisateur doit définir bon * nom d’utilisateur * et * mot de passe * pour la base de données.
Certains des paramètres qui peuvent être configurés pour le pool de connexion JNDI sont comme suit :
** maxActive **: le nombre de connexions actives maximales à utiliser.
** maxIdle **: le nombre de nombre maximal de connexions inutilisé.
** maxWait **: le nombre maximal de ** millisecondes ** qui attendra la piscine.
** poolPreparedStatements **: activez l’instruction préparée, mise en commun (très important pour un meilleur rendement).
** maxOpenPreparedStatements **: le nombre maximal de requêtes préparées dans la piscine.
** validationQuery **: (valeur par défaut null) A validation requête que double vérifie la connexion est encore en vie avant de l’utiliser réellement.
** timeBetweenEvictionRunsMillis **: (par défaut -1) le nombre de ** millisecondes ** dormir entre les exécutions du thread inactif objet expulse. Lorsque non positive, aucun thread n’expulse objet inactif ne sera exécutée.
** numTestsPerEvictionRun **: (par défaut 3) le nombre d’objets à examiner au cours de chaque exécution du thread inactif objet expulse (le cas échéant).
** minEvictableIdleTimeMillis **:: (par défaut de 1000 * 60 * 30) le minimum de temps, in ** millisecondes **, un objet peut siéger ralenti dans la piscine avant qu’il soit admissible à l’éviction de l’expulse de l’objet inactif (le cas échéant).
** removeAbandoned **: (false par défaut) drapeau pour supprimer les connexions abandonnées si elles dépassent le removeAbandonedTimout. Si la valeur true, une connexion est considérée comme abandonnée et admissibles pour le retrait s’il a été ralenti plus longtemps que le removeAbandonedTimeout. Ceci affectant la valeur true peut récupérer db connexions provenant d’applications mal écrites qui ne parviennent pas à fermer une connexion.
** removeAbandonedTimeout **: (par défaut 300) Timeout en ** secondes ** avant une connexion abandonnée peut être retirée.
** logAbandoned **: (false par défaut) drapeau pour enregistrer les traces de la pile pour le code d’application qui abandonne une instruction ou une connexion.
** testWhileIdle **: (false par défaut) drapeau utilisé pour tester les connexions en cas d’inactivité.
Avertissement
Les paramètres précédents devraient être modifiées que par des utilisateurs expérimentés. À l’aide de fausses valeurs faibles pour ** removedAbandonedTimeout ** et ** minEvictableIdleTimeMillis ** peut entraîner des échecs de connexion ; Si oui, essayez il est important de mettre en place ** logAbandoned ** true et vérifier votre fichier de log catalina.out.
Plus d’informations sur les paramètres se trouvent à la » documentation DBCP <http: commons.apache.org/proper/commons-dbcp/configuration.html=”“>’ _.</http:>
Installation de GeoServer¶
Lancer GeoServer et accédez à la : menuselection : section « Magasins–> Add new Store ».
Tout d’abord, choisissez le * PostGIS (JNDI) * datastore et donnez-lui un nom :
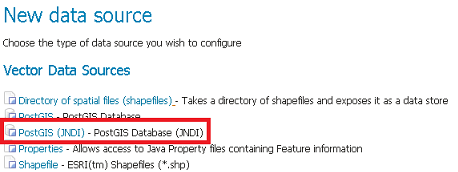
Configuration du magasin de JNDI de PostGIS
Et puis, vous pouvez configurer le pool de connexions :
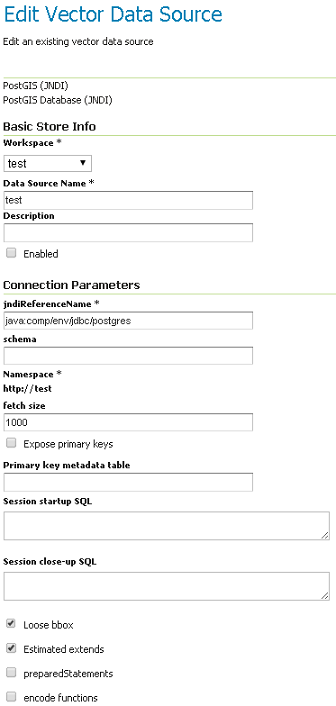
Configuration du magasin de JNDI de PostGIS
Lorsque vous faites cela, assurez-vous que le schéma est configuré correctement, ou le magasin de données répertorie toutes les tables, à Qu’on peut trouver dans le schéma, qu’il est donné accès.
Configuration de Microsoft SQLServer JNDI¶
Avant de configurer un pool de connexions SQL Server, vous devez suivre ces “lignes directrices <http: docs.geoserver.org/stable/en/user/data/database/sqlserver.html=”“>’ _.</http:>
Avertissement
Vous devez supprimer le : file:’sqljdbc.jar‘ fichier depuis le dossier “WEB-INF/lib ‘’ et placez-le dans le dossier ‘’ $TOMCAT_HOME/lib ‘’.
Installation de Tomcat¶
Dans ce cas, nous allons configurer une DataSource JNDI pour une base de données SQL Server. Vous doit créer/modifier le fichier context.xml à l’intérieur de $TOMCAT_HOME/conf répertoire contenant les lignes suivantes:
<Context>
<Resource
name="jdbc/sqlserver"
auth="Container"
type="javax.sql.DataSource"
url="jdbc:sqlserver://localhost:1433;databaseName=test;user=admin;password=admin;"
driverClassName="com.microsoft.sqlserver.jdbc.SQLServerDriver"
username="admin"
password="admin"
maxActive="20"
maxIdle="10"
maxWait="10000"
minEvictableIdleTimeMillis="300000"
timeBetweenEvictionRunsMillis="300000"
validationQuery="SELECT 1"/>
</Context>
Note
Notez que ** base de données nom **, ** username ** et ** ** mot de passe doivent être définis directement dans l’URL.
Installation de GeoServer¶
Lancer GeoServer et accédez à la : menuselection : section « Magasins–> Add new Store ».
Puis choisissez le * Microsoft SQL Server (JNDI) * datastore et donnez-lui un nom :
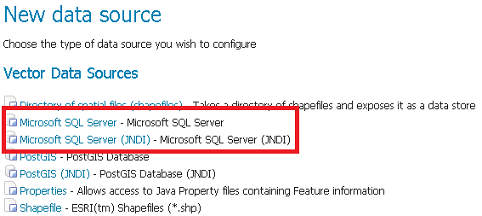
Configuration de Microsoft SQLServer JNDI magasin
Après, vous pouvez configurer le pool de connexions :
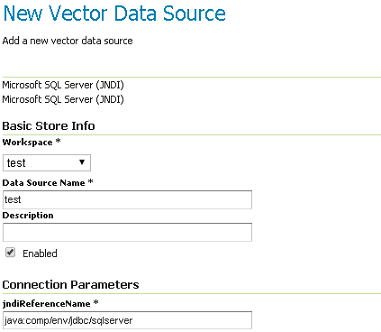
Configuration de Microsoft SQLServer JNDI magasin
Configuration JNDI Oracle¶
Avant de configurer un pool de connexion Oracle, vous devez télécharger le plugin de l’Oracle de la ‘ GeoServer Télécharger Page <http: geoserver.org/download/=”“>’ _ et puis mettre le le : file:’ojdbc14.jar‘ fichier dans le dossier ‘’ $TOMCAT_HOME/lib ‘’.</http:>
Avertissement
Vous devez supprimer le : file:’ojdbc14.jar‘ fichier depuis le dossier “WEB-INF/lib ‘’ et placez-le dans le dossier ‘’ $TOMCAT_HOME/lib ‘’.
Installation de Tomcat¶
Tout d’abord vous devez créer/modifier le fichier context.xml à l’intérieur de ‘’ $TOMCAT_HOME/conf ‘’ répertoire contenant les lignes suivantes:
<Context>
<Resource
name="jdbc/oralocal"
auth="Container" type="javax.sql.DataSource"
url="jdbc:oracle:thin:@localhost:1521:xe"
driverClassName="oracle.jdbc.driver.OracleDriver"
username="dbuser"
password="dbpasswd"
maxActive="20"
maxIdle="3"
maxWait="10000"
minEvictableIdleTimeMillis="300000"
timeBetweenEvictionRunsMillis="300000"
poolPreparedStatements="true"
maxOpenPreparedStatements="100"
validationQuery="SELECT SYSDATE FROM DUAL" />
</Context>
Installation de GeoServer¶
Lancer GeoServer et accédez à la : menuselection : section « Magasins–> Add new Store ».
Puis choisissez le * Oracle NG (JNDI) * datastore et donnez-lui un nom :
Configuration d’Oracle JNDI magasin
Après, vous pouvez configurer le pool de connexions :
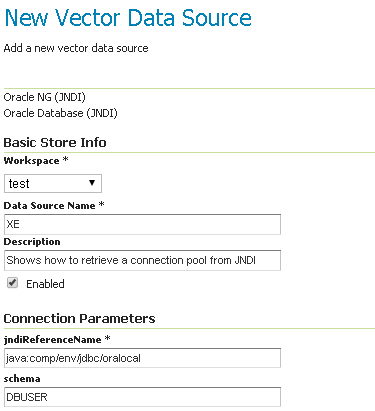
Configuration d’Oracle JNDI magasin
Note
Dans Oracle, le schéma est généralement le nom d’utilisateur, supérieur casse mixte.
Configuration des Pools de connexions pour l’utilisation de la production¶
Temps d’attente de connexion et de la relation avec les autres params¶
En général, il est important de définir le temps de connexion en attente d’une manière que le pool de connexion ne devienne pas un endroit où faire la queue discussions à exécuter les demandes en vertu de grosse charge. Il est en effet possible que sous de grands filets de charge à exécuter les demandes pour une couche vectorielle seront plus nombreux que les connexions disponibles dans la piscine où ces discussions seront bloqués essayer d’acquérir une nouvelle connexion; si le nombre de connexions est beaucoup plus petit que le nombre de demandes reçues et le temps maximum d’attente est assez grand (par exemple 60 secondes), nous allons nous retrouver dans la condition d’avoir de nombreux threads en attente depuis longtemps d’acquérir une connexion après que la plupart des les ressources dont ils ont besoin seront attribuées, en particulier la mémoire tampon d’arrière si ceux-ci sont WMS demandes.
Le max wait time en général doit être réglé en conséquence le délai d’exécution maximal prévu pour un demandes, de bout-en-bout. Cela inclut des choses comme, l’accès au système de fichiers, le chargement des données. Comme exemple, si nous prenons en compte les WMS demandes que nous sommes autorisés à spécifier un temps de réponse maximal, donc si définir ce à N secondes, le temps d’attente maximum devrait être fixé à une valeur inférieure à celle puisque nous ne voulons pas gaspiller des ressources ayant threads bloqués inutilement en attente d’une connexion. Dans ce cas, il est préférable de ne pas rapide pour libérer des ressources qui pourraient être utilisées autrement inutilement.
Maximiser la mise en commun des Pools de connexions¶
- Comment les données sont organisées entre la base de données, des schémas et des tableau incidence du degré de flexibilité, que nous avons en essayant de mieux partager des connexions, indépendamment du fait que nous utilisions JNDI avec Betclic ou non. En Résumé :
Fractionnement des tables dans les schémas nombreux rend difficile pour GeoServer à table access appartenant à différents schémas, à moins que nous basculons vers JNDI, étant donné que le schéma doit être spécifié dans le cadre de la params de connexion lors de l’utilisation des piscines intérieures
En utilisant différents utilisateurs pour les différents schémas empêchent JNDI de travailler efficacement dans l’ensemble de schémas. Il est préférable d’utiliser lorsque possible un seul dédié compte à travers des schémas
Ayant en général une combinaison complexe d’utilisateurs et de schéma peut conduire à répartition inefficace des connexions disponibles dans plusieurs pools
Longue histoire courte, chaque fois qu’il est possible s’efforcent de faire usage d’un petit nombre d’utilisateurs et si ne pas utiliser JNDI à un petit nombre de schéma, bien que JNDI est un must pour Organisation désireux de créer un complexe mis en place où les différents espaces de travail (c.-à-d. Services virtuels) servent le même contenu différemment.
Validation de la requête¶
Peu importe comment nous configurer la requête de validation, il est extrêmement important que nous nous souvenions toujours valider les connexions avant de les utiliser dans GeoServer ; ne pas le faire pourrait conduire à des erreurs en raison de connexions rassises assis la piscine. Ceci peut être réalisé avec le pool de connexion interne (via la boîte de connexions validate) ainsi qu’avec les piscines déclarées dans JNDI (via le mécanisme de requête de validation) ; Il est intéressant de rappeler que ce dernier passera à configurabilité de grain plus fine.
Notes
| [1] | http://en.wikipedia.org/wiki/Java_Naming_and_Directory_Interface |
| [2] | http://commons.apache.org/proper/commons-dbcp/ |